
604 字
3 分钟
使用 AI 推理一键获取人声 MIDI:Vocal2Midi 项目体验

最近在折腾 UTAU,刚好在 B 站主页刷到了 Vocal2Midi 的介绍视频,品鉴了一下,感觉这个效果确实挺惊艳的,遂在这里分享一下。
Vocal2Midi 是一款基于 AI 推理的开源人声转 MIDI 工具,专为虚拟歌姬(UTAU / Vocaloid 等)工作流设计。相比传统手动扒谱或简单的音高提取工具,它在歌词对齐、音高识别和节奏还原上都有显著提升,能直接输出可编辑的 MIDI、UTAU 工程文件(USTX)以及歌词对齐辅助文件,大幅降低了“人声 → 虚拟歌姬”的门槛。
附上作者的演示视频
核心亮点
(copy至原视频的)
- 从原始人声直接产出 MIDI / USTX / 对齐辅助文件:无需手动逐字对轨,一步生成虚拟歌姬可用的工程文件。
- 良好的汉语普通话与日语歌词灌注支持:对中文和日文歌曲的歌词识别与对齐效果优秀,减少了后期修词工作量。
- 支持使用现有歌词文件进行匹配,增强识别准确率:如果你已有歌词文本,可以直接导入进行强制对齐,进一步提升转写精度。
- 较低的配置需求,兼容市面主流配置:虽然内置了大模型,但推理效率经过优化,主流中端显卡即可流畅运行。
实际体验
vocal2midi使用了Qwen3-ASR-1.7B和GAME-1.0.3-medium的模型,全部解压完后吃了我10.2G的空间,占用还蛮大的其实。
实际体验下来,生成的人声MIDI只需稍作修改就能达到合格甚至更好的标准,错音、词不对的现象很少见,效果比 X Studio 和 ACE Studio 的人声提取要强太多了。
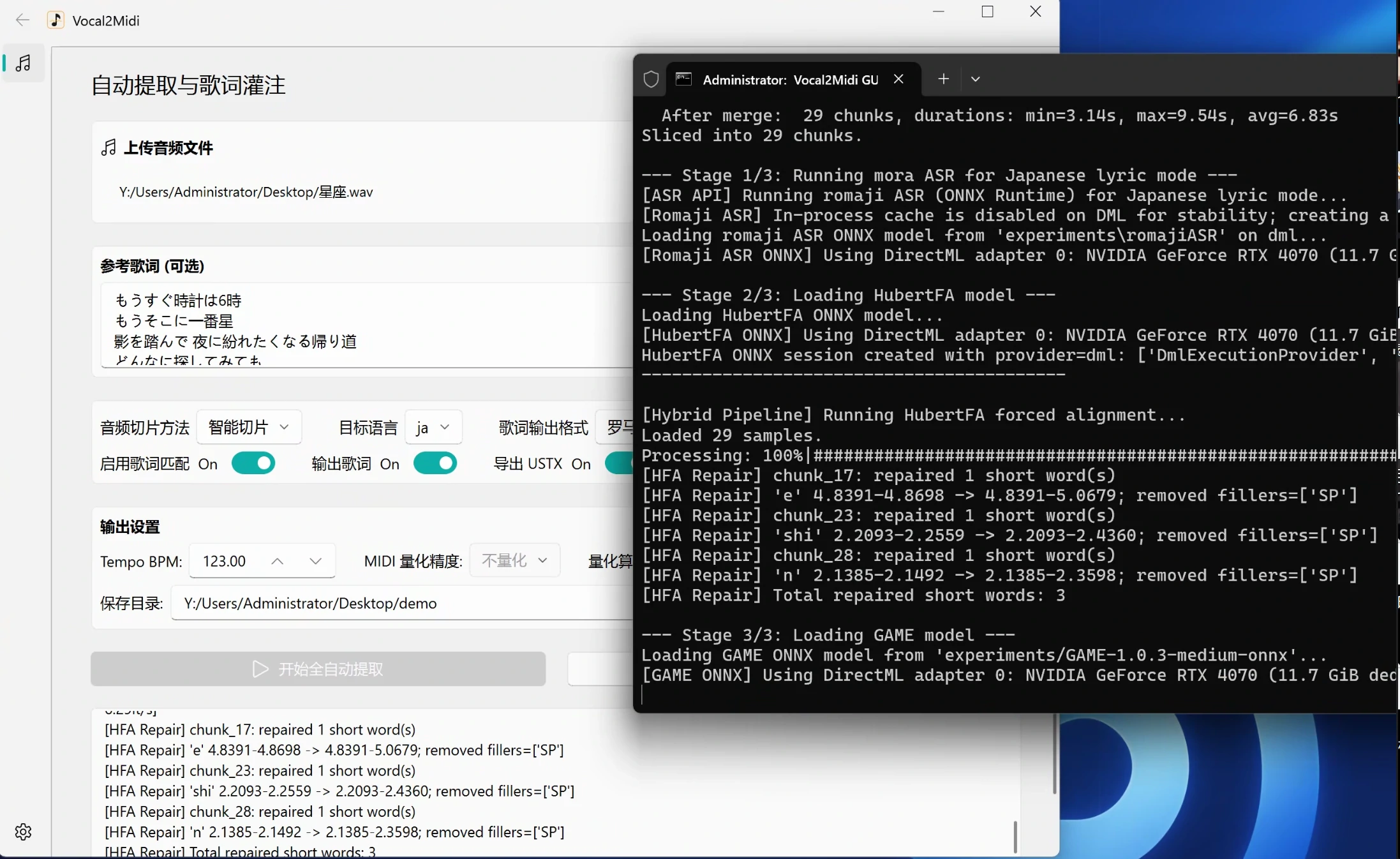
使用的话也很简单,准备好干声和歌词,无脑填进软件即可。 然后一键推理,放松一下大脑,拿文件,完事。
我用的显卡是 RTX 4070,测试结果贴下面了,供参考:
- 测试音频:一首约 4 分钟的歌曲(若能化为星座)
- 显卡:NVIDIA RTX 4070
- 推理耗时:约 32 秒
这个速度体感还是非常快的,比想象中快不少,演示视频过会在贴这里吧。
使用 AI 推理一键获取人声 MIDI:Vocal2Midi 项目体验
https://flygeon.top/posts/5/ 相关文章
12345
对个人主页进行了重构并迁移了框架
有趣的项目将原来的Svelte的个人主页重构为Next.js,大幅重构了页面,整体屎山得到优化
简单做了一个 Flutter 架构开发的跨平台媒体库,简单记录一下开发历程
有趣的项目由于神人微软的 Windows 媒体管理过于混乱,音频、视频、图片各管各的,导致用起来非常难受。于是我就简单写了一个媒体库,使用 Material Design 风格将这些媒体聚集在一起,方便了管理。
开发了一个个人导航页
有趣的项目一款基于 Svelte 5 + Vite 6 的暗黑风个人导航页,具有包含动态粒子特效、音乐播放器、博客文章时间线显示等功能,可以通过 Cookie 持久化用户设置,适配移动端与桌面端。
做了一个可以让大家视奸我的网站
有趣的项目欢迎大家访问me.flygeon.top来视奸我喵
为你的博客生成封面图吧
有趣的项目基于 afroim/easy_cover 二次开发的博客封面生成工具,新增深色模式、配置保存与导入导出,方便风格复用。